overfitting:過度學習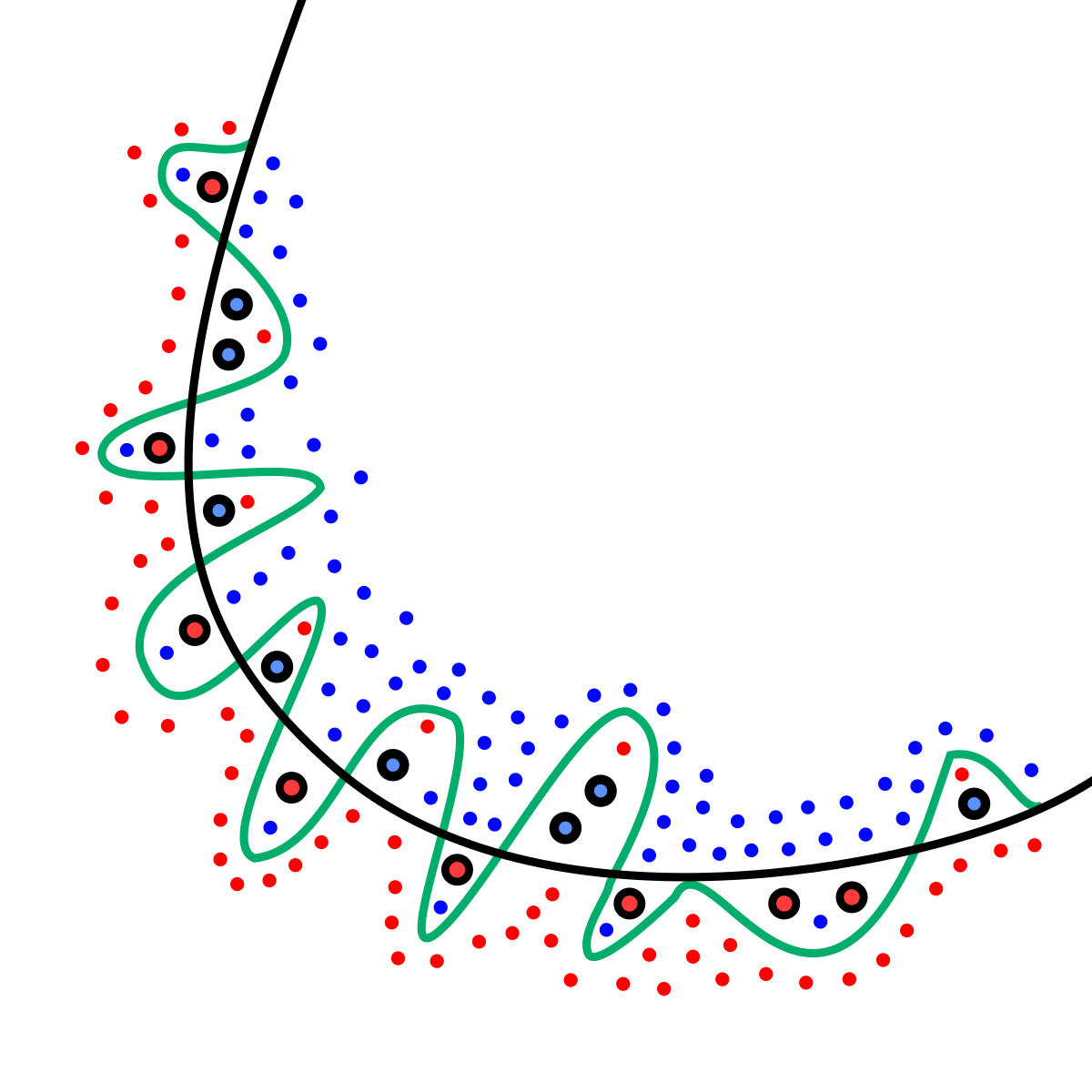
假設今天我們是要把紅色點點和藍色點點分開,我們期望找到的是黑色的線也就是正規劃後的結果,而綠色的線則是overfitting的結果,雖然他正確的將紅色和藍色的點分開了,在訓練時準確率高,但是在未知資料上的準確率低。
可以參考這篇文章的解釋:
https://medium.com/雞雞與兔兔的工程世界/機器學習-ml-note-overfitting-過度學習-6196902481bb
上一篇文章將隱藏層神經元改為1000個後overfitting的狀況變嚴重了,所以這邊要使用DropOut功能來避免。
Dropout(0.5)在每次調整迭代時,會隨機在隱藏層中放棄50%的神經元來避免Overfitting
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
model = Sequential()
model.add(Dense(units=1000,input_dim=784,kernel_initializer='normal',activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=10,kernel_initializer='normal',activation='softmax'))
print(model.summary())
輸出模型摘要:
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
train_history=model.fit(x=x_Train_normalize,y=y_Train_OneHot,validation_split=0.2,epochs=10,batch_size=200,verbose=2)
輸出訓練結果:
show_train_history(train_history,'accuracy','val_accuracy')
輸出:
可以看到overfitting的問題被改善,accuracy和val_accuracy的差距變小。

